
7月6日-8日,信百會(huì)2024年度研討會(huì)在清華大學(xué)經(jīng)濟(jì)管理學(xué)院隆重舉行��。在本次年度研討會(huì)主論壇上�����,中國(guó)工程院院士���,清華大學(xué)計(jì)算機(jī)系教授鄭緯民作了題為《算力和存儲(chǔ)是人工智能大模型的基座》的主題演講��。
他詳細(xì)介紹了支持大模型訓(xùn)練的三種算力系統(tǒng)(基于英偉達(dá)公司 GPU 的系統(tǒng)�、基于國(guó)產(chǎn)通用 GPU 芯片的系統(tǒng)��、基于超級(jí)計(jì)算機(jī)的系統(tǒng)),以及人工智能大模型對(duì)存儲(chǔ)的需求與挑戰(zhàn)���。他認(rèn)為��,設(shè)計(jì)大模型基礎(chǔ)設(shè)施需要考慮五個(gè)問(wèn)題:一是半精度運(yùn)算性能與雙精度運(yùn)算性能的平衡��,二是網(wǎng)絡(luò)平衡設(shè)計(jì)���,三是內(nèi)存平衡設(shè)計(jì),四是 IO 子系統(tǒng)平衡設(shè)計(jì)����,五是如果是國(guó)產(chǎn) AI 芯片的系統(tǒng),還需要做好編程框架�����、并行加速等 10 個(gè)軟件����。“這五點(diǎn)如果做得好��,別人要用 1 萬(wàn)塊卡,我們用 9000 塊卡就可以了�����?�!彼赋?�。
(本文根據(jù)鄭緯民院士在信百會(huì)2024年度研討會(huì)上的現(xiàn)場(chǎng)發(fā)言內(nèi)容整理)

人工智能基礎(chǔ)大模型正經(jīng)歷從單模態(tài)向多模態(tài)的演進(jìn)�����。最初僅限于文本處理����,隨后擴(kuò)展到圖像識(shí)別���,如今已涉及視頻分析�����。人工智能在醫(yī)療���、汽車、制造、礦山和氣象等領(lǐng)域的應(yīng)用正發(fā)生顯著變化���。這種發(fā)展對(duì)算力產(chǎn)生了爆發(fā)性需求��,大模型生命周期的每個(gè)環(huán)節(jié)都需要強(qiáng)大的計(jì)算能力����。

大模型開發(fā)主要包括四個(gè)階段:模型開發(fā)�����、模型訓(xùn)練�、模型精調(diào)和模型推理。在模型開發(fā)階段�,需要優(yōu)化程序以提高效率。模型訓(xùn)練階段耗時(shí)頗長(zhǎng)��,例如 GPT-4 使用一萬(wàn)塊 A100 GPU����,訓(xùn)練時(shí)間長(zhǎng)達(dá) 11 個(gè)月。訓(xùn)練數(shù)據(jù)主要來(lái)源于互聯(lián)網(wǎng)�,涵蓋工業(yè)、農(nóng)業(yè)�、娛樂(lè)等多個(gè)領(lǐng)域�,由此形成的模型稱為基礎(chǔ)大模型��。模型精調(diào)階段則針對(duì)特定領(lǐng)域進(jìn)行專門訓(xùn)練��,如醫(yī)療或金融�����,以提升模型在特定領(lǐng)域的表現(xiàn)���。
模型完成后,在處理用戶請(qǐng)求時(shí)也需要大量算力��。
無(wú)論是模型訓(xùn)練還是推理��,都對(duì)算力有巨大需求���。
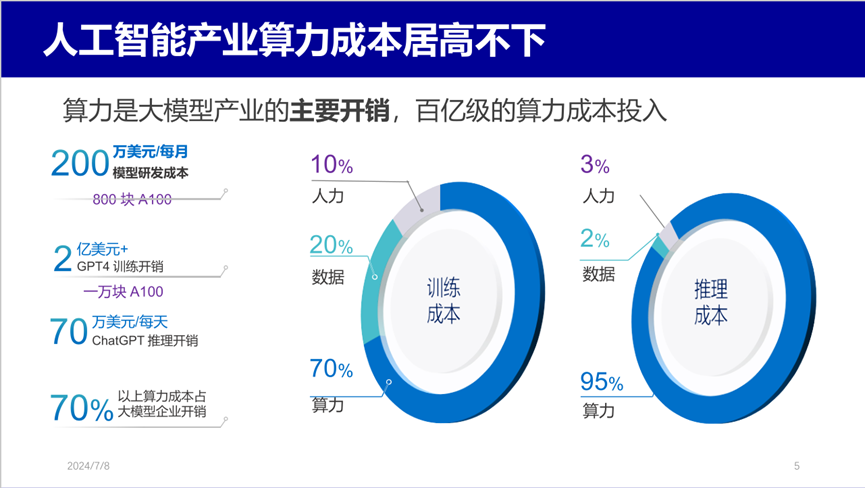
在模型訓(xùn)練成本中���,算力約占 70%,數(shù)據(jù)占 20%�,人力僅占 10%。而在推理階段���,算力成本更是高達(dá) 95%����。
支持大模型訓(xùn)練的三種算力系統(tǒng)
目前支持大模型訓(xùn)練的系統(tǒng)主要有三種:基于 NVIDIA GPU 的系統(tǒng)、基于國(guó)產(chǎn) AI 芯片的系統(tǒng)�����,以及基于超級(jí)計(jì)算機(jī)的系統(tǒng)�。NVIDIA 系統(tǒng)因其出色的硬件性能和良好的生態(tài)系統(tǒng)而備受青睞,但由于政治因素��,其供應(yīng)受到限制�,價(jià)格大幅上漲。近年來(lái)�����,國(guó)產(chǎn) AI 芯片系統(tǒng)在硬件和軟件方面都取得了顯著進(jìn)展�。然而,用戶對(duì)國(guó)產(chǎn)系統(tǒng)的接受度仍然不高����,主要原因在于其生態(tài)系統(tǒng)尚未完善。一個(gè)良好的生態(tài)系統(tǒng)應(yīng)當(dāng)能夠使原本為 NVIDIA 平臺(tái)開發(fā)的人工智能軟件輕松遷移到國(guó)產(chǎn)系統(tǒng)上����。目前�����,國(guó)產(chǎn)系統(tǒng)在軟件兼容性和開發(fā)便利性方面仍有待改進(jìn)���。為改變這一局面,需要開發(fā)好十個(gè)關(guān)鍵軟件�����,以增強(qiáng)國(guó)產(chǎn)系統(tǒng)的生態(tài)競(jìng)爭(zhēng)力��。
國(guó)產(chǎn)軟件生態(tài)需要做好的幾件事

大模型軟件開發(fā)目前面臨多方面的挑戰(zhàn)�,主要包括以下幾個(gè)方面:
首先��,框架的構(gòu)建至關(guān)重要���。現(xiàn)代大模型軟件不再直接基于硬件編寫�����,而是依賴于框架開發(fā)���,這大大提高了開發(fā)效率�。其次��,并行加速技術(shù)亟待提升���。當(dāng)前的大模型訓(xùn)練普遍采用多卡并行方式��。雖然我國(guó)自主研發(fā)的卡性能已達(dá)到一定水平���,但在并行加速方面仍有待改進(jìn)。第三���,通信庫(kù)的優(yōu)化不容忽視�。卡與卡之間的通信效率直接影響整體性能�,因此高效的通信庫(kù)成為關(guān)鍵。第四��,算子庫(kù)的完善同樣重要����。例如,高性能的矩陣乘法庫(kù)可以顯著提升計(jì)算效率��。第五,AI 編譯器的開發(fā)面臨挑戰(zhàn)��。將軟件編譯至國(guó)產(chǎn)芯片上是一個(gè)復(fù)雜的過(guò)程����,而國(guó)內(nèi)在編譯器領(lǐng)域的專業(yè)人才相對(duì)匱乏。此外��,還包括編程語(yǔ)言��、調(diào)度器�、內(nèi)存分配、容錯(cuò)系統(tǒng)����、存儲(chǔ)系統(tǒng)等在內(nèi)的多個(gè)關(guān)鍵組件����,總計(jì)約 10 個(gè)核心軟件。雖然這些軟件都有一定進(jìn)展��,但或是覆蓋不夠全面�,或是質(zhì)量有待提高。我一直呼吁����,芯片生產(chǎn)廠商應(yīng)當(dāng)主導(dǎo)這 10 個(gè)軟件的開發(fā)�。只有將這些基礎(chǔ)設(shè)施做好��,才能吸引更多開發(fā)者使用國(guó)產(chǎn)軟件棧��,從而推動(dòng)整個(gè)行業(yè)的發(fā)展��。
目前�����,即便國(guó)產(chǎn)計(jì)算卡的硬件性能只達(dá)到國(guó)外產(chǎn)品的 50% 至 60%���,只要能夠完善相關(guān)的 10 個(gè)核心軟件�,仍能獲得客戶的認(rèn)可和使用�����。當(dāng)前���,用戶對(duì)國(guó)產(chǎn)計(jì)算卡的接受度不高����,主要原因并非硬件性能不足。事實(shí)上��,大多數(shù)用戶并未明顯感受到硬件性能的差異����,他們更關(guān)注的是生態(tài)系統(tǒng)的完善程度。值得注意的是���,即使國(guó)產(chǎn)硬件性能超越國(guó)外產(chǎn)品 20%�����,如果這 10 個(gè)軟件未能得到充分開發(fā)和優(yōu)化����,用戶依然會(huì)對(duì)國(guó)產(chǎn)方案望而卻步��。因此��,我們可以認(rèn)識(shí)到�,在硬件性能達(dá)到一定水平后���,軟件生態(tài)系統(tǒng)的建設(shè)將成為決定產(chǎn)品成敗的關(guān)鍵因素��。
我國(guó)目前擁有多個(gè)高性能超級(jí)計(jì)算機(jī)系統(tǒng)���,其中科技部正式認(rèn)定的有 14 個(gè)�����,實(shí)際數(shù)量更多����。這些超級(jí)計(jì)算機(jī)投資巨大����,單臺(tái)造價(jià)可達(dá) 10 億至 20 億元,性能卓越�����,為國(guó)民經(jīng)濟(jì)發(fā)展�、國(guó)防建設(shè)和提升人民生活水平做出了重要貢獻(xiàn)。鑒于這些高性能計(jì)算系統(tǒng)的強(qiáng)大能力��,我們不禁思考:能否將其用于大模型訓(xùn)練����?這是一個(gè)值得探討的問(wèn)題�����。另一個(gè)值得關(guān)注的現(xiàn)狀是�,部分超級(jí)計(jì)算機(jī)的使用率并未達(dá)到最高���。針對(duì)這一情況���,我們進(jìn)行了一系列實(shí)驗(yàn),重點(diǎn)探索軟硬件協(xié)同設(shè)計(jì)的可行性���。軟硬件協(xié)同設(shè)計(jì)的核心理念是:軟件開發(fā)人員需深入了解硬件架構(gòu)����,只有這樣�,才能開發(fā)出真正高效的軟件。
以天氣預(yù)報(bào)軟件為例�,說(shuō)明軟硬件協(xié)同的重要性。早期的天氣預(yù)報(bào)軟件主要由大氣物理專業(yè)畢業(yè)生開發(fā)的���。當(dāng)時(shí)的計(jì)算機(jī)硬件相對(duì)簡(jiǎn)單,主要依賴 CPU,memory 和磁盤,開發(fā)者只需掌握一門編程語(yǔ)言和基本的數(shù)據(jù)結(jié)構(gòu)知識(shí)即可���。然而����,近十幾年來(lái)����,計(jì)算機(jī)硬件架構(gòu)發(fā)生了巨大變革。除了傳統(tǒng)的 CPU�����,還出現(xiàn)了 GPU����、TPU、DPU 以及 SSD 等新型硬件�����。如果開發(fā)者仍局限于傳統(tǒng)的 CPU 知識(shí)���,而對(duì)新型硬件如 GPU 缺乏了解���,那么開發(fā)的軟件要么無(wú)法正常運(yùn)行���,要么運(yùn)行效率極低,無(wú)法充分利用硬件資源����。只有當(dāng)軟件能夠充分利用各種硬件資源,我們才能稱之為實(shí)現(xiàn)了真正的軟硬件協(xié)同���。這種協(xié)同對(duì)于提升超級(jí)計(jì)算機(jī)在大模型訓(xùn)練等領(lǐng)域的應(yīng)用效率至關(guān)重要���。

我們?cè)谇鄭u的一臺(tái)高性能計(jì)算機(jī)上進(jìn)行了實(shí)驗(yàn)。這臺(tái)計(jì)算機(jī)不僅是我國(guó)性能最強(qiáng)的設(shè)備����,在國(guó)際范圍內(nèi)也位居前列。我們選擇將 LAMA 和百川兩個(gè)大模型部署到這臺(tái)高性能計(jì)算機(jī)上進(jìn)行訓(xùn)練�,同時(shí)確保訓(xùn)練結(jié)果的準(zhǔn)確性。通過(guò)對(duì)比實(shí)驗(yàn)��,我們發(fā)現(xiàn)��,相較于在傳統(tǒng)高性能計(jì)算機(jī)上進(jìn)行訓(xùn)練�,將模型在 NVIDIA 的 GPU 上訓(xùn)練�,成本可以大幅降低至原來(lái)的 1/6 左右��。值得注意的是���,這臺(tái)高性能計(jì)算機(jī)是國(guó)家投資購(gòu)置的,用它來(lái)進(jìn)行大模型訓(xùn)練的成本相對(duì)低廉�����。為了說(shuō)明成本優(yōu)勢(shì)��,我舉例說(shuō)明:有一家機(jī)構(gòu)在進(jìn)行大模型訓(xùn)練時(shí)�����,總計(jì)花費(fèi)了 4500 萬(wàn)元人民幣���。這個(gè)價(jià)格在業(yè)內(nèi)被認(rèn)為是比較標(biāo)準(zhǔn)的���。然而,我建議他們考慮在青島的這臺(tái)高性能計(jì)算機(jī)上進(jìn)行訓(xùn)練�����,因?yàn)榘凑瘴覀兊挠?jì)算,只需要用原來(lái)成本的 1/6 就能完成相同的訓(xùn)練任務(wù)���。對(duì)于大模型訓(xùn)練��,我們并不建議專門購(gòu)置高性能計(jì)算機(jī)��,因?yàn)槠涑杀具^(guò)高�����,可達(dá) 20 億元���。這種投資規(guī)模通常只有國(guó)家級(jí)項(xiàng)目才能承擔(dān)。
人工智能大模型對(duì)存儲(chǔ)的需求與挑戰(zhàn)
在大模型的全生命周期中��,存儲(chǔ)系統(tǒng)在每個(gè)環(huán)節(jié)都扮演著至關(guān)重要的角色�����。我們需要從整體角度審視訓(xùn)練和推理過(guò)程���,包括數(shù)據(jù)的獲取與處理���。對(duì)于大模型而言�,數(shù)據(jù)量越大越好����,且呈現(xiàn)多模態(tài)特征,包括文本���、視頻等多種形式。這些數(shù)據(jù)的一個(gè)顯著特點(diǎn)是以大量小文件的形式存在�����。如何高效管理和處理這些數(shù)量龐大的小文件�,對(duì)計(jì)算機(jī)的存儲(chǔ)系統(tǒng)提出了嚴(yán)峻的挑戰(zhàn)。
在大模型訓(xùn)練過(guò)程中�,數(shù)據(jù)預(yù)處理環(huán)節(jié)的重要性不容忽視。為確保訓(xùn)練效果�,必須對(duì)原始數(shù)據(jù)進(jìn)行嚴(yán)格的清洗和篩選。數(shù)據(jù)質(zhì)量與最終模型性能呈正相關(guān)關(guān)系���,高質(zhì)量的數(shù)據(jù)集能夠顯著提升模型效果���。以 GPT-4 的訓(xùn)練為例,整個(gè)過(guò)程耗時(shí) 11 個(gè)月�,使用了約一萬(wàn)塊計(jì)算卡����。值得注意的是�,在這 11 個(gè)月的訓(xùn)練周期中,接近一半的時(shí)間用于數(shù)據(jù)處理�����。這一事實(shí)凸顯了數(shù)據(jù)預(yù)處理在整個(gè)訓(xùn)練流程中的關(guān)鍵地位���。如果我們能夠優(yōu)化存儲(chǔ)系統(tǒng)�,提高數(shù)據(jù)處理效率���,就有可能將總體訓(xùn)練時(shí)間從 11 個(gè)月縮短至 10 個(gè)月�����,甚至 9 個(gè)月��。這種時(shí)間上的節(jié)省不僅能夠加速模型開發(fā)進(jìn)程�,還能降低整體訓(xùn)練成本�����。
第三是模型訓(xùn)練,第四是模型推理�����。整個(gè)過(guò)程����,都跟存儲(chǔ)器有關(guān)系。
在大模型應(yīng)用的推理階段����,存儲(chǔ)系統(tǒng)的優(yōu)化同樣發(fā)揮著關(guān)鍵作用��。
最近����,我與一家上海的芯片公司合作,通過(guò)對(duì)存儲(chǔ)系統(tǒng)進(jìn)行改進(jìn)���,我們?nèi)〉昧孙@著的性能提升���。具體而言,經(jīng)過(guò)優(yōu)化的存儲(chǔ)系統(tǒng)使得推理性能提高了數(shù)倍。這一進(jìn)步的意義非常重大��,因?yàn)樗苯佑绊懙接布度氲囊?guī)模���。
性能的倍數(shù)級(jí)提升意味著����,為達(dá)到同等推理能力��,所需購(gòu)買的計(jì)算卡數(shù)量可以大幅減少�����。
設(shè)計(jì)大模型基礎(chǔ)設(shè)施需要考慮的五個(gè)問(wèn)題
對(duì)于國(guó)家重點(diǎn)發(fā)展的萬(wàn)卡系統(tǒng)項(xiàng)目�,即建設(shè)一萬(wàn)塊國(guó)產(chǎn)計(jì)算卡的系統(tǒng),我們需要特別關(guān)注五個(gè)關(guān)鍵方面�����。其中����,
首要考慮的是半精度運(yùn)算性能與全精度運(yùn)算性能之間的平衡。
具體而言���,我們首先需要評(píng)估其在處理 16 位二進(jìn)制數(shù)(即半精度)和 64 位二進(jìn)制數(shù)(即全精度)時(shí)的加減乘除運(yùn)算性能�����。在人工智能應(yīng)用中���,16 位運(yùn)算的性能尤為重要����,這一點(diǎn)毋庸置疑�。然而,64位運(yùn)算性能同樣不容忽視��。理想情況下���,64 位運(yùn)算與 16 位運(yùn)算的性能比應(yīng)當(dāng)保持在 1:50 到 1:100 之間�����。這種平衡能夠確保系統(tǒng)在處理需要高精度計(jì)算的任務(wù)時(shí)仍具備足夠的能力,同時(shí)又能在人工智能等主要應(yīng)用場(chǎng)景中發(fā)揮出色的性能�����。
第二個(gè)問(wèn)題是網(wǎng)絡(luò)平衡設(shè)計(jì),
一萬(wàn)塊 AI 卡購(gòu)買回來(lái)之后�,如何將它們連接起來(lái)?有人可能會(huì)問(wèn)����,這一萬(wàn)塊卡之間是否可以直接互聯(lián),從而實(shí)現(xiàn)最快的通信速度�?理論上,如果每?jī)蓧K卡之間都能夠直接通信�����,通信效率將非常高���。然而�,這樣的設(shè)計(jì)意味著每塊 AI 卡需要與其他 9999 塊卡直接連接�����,造成了巨大的連接成本�。一塊 AI 卡需要插入 9999 塊連接卡,整個(gè)系統(tǒng)就需要 9999×10000 塊連接卡�。如此一來(lái),連接卡的成本將遠(yuǎn)遠(yuǎn)超過(guò) AI 卡本身的成本�。即使在資金充足的情況下�,這種方式依然存在問(wèn)題����。單臺(tái)機(jī)器需要插入 9999 塊連接卡,但物理空間有限��,不可能容納這么多連接卡�。那么,該如何解決這一連接問(wèn)題呢���?有一個(gè)相對(duì)簡(jiǎn)單的辦法:將一萬(wàn)塊 AI 卡分成每組 100 塊卡���,組內(nèi)的卡之間直接互聯(lián),這樣每塊卡只需插入 99 塊連接卡�����。每組的 100 塊卡都遵循這一連接方式�����,而組與組之間的通信則需要通過(guò)多步中繼平均來(lái)實(shí)現(xiàn)����。
第三,關(guān)于內(nèi)存平衡設(shè)計(jì)�����。
內(nèi)存的管理非常重要�����,特別是在處理大數(shù)據(jù)時(shí)��,必須確保不會(huì)出現(xiàn)堵塞的情況�����。
第四�,關(guān)于 IO 子系統(tǒng)平衡設(shè)計(jì)。
當(dāng)我們將一萬(wàn)塊卡片連在一起時(shí)�,通常每幾個(gè)小時(shí)會(huì)出現(xiàn)一次錯(cuò)誤?��?赡苡腥藭?huì)疑惑�,為什么錯(cuò)誤頻率如此之高�?事實(shí)上,這已經(jīng)是世界先進(jìn)水平的表現(xiàn)了���。由于卡片數(shù)量龐大�����,錯(cuò)誤的出現(xiàn)頻率不可避免�,大約每三到四個(gè)小時(shí)就會(huì)出現(xiàn)一次。在進(jìn)行訓(xùn)練時(shí)��,如果訓(xùn)練只進(jìn)行一周�����,并在此期間觀察錯(cuò)誤的發(fā)生情況�。假設(shè)系統(tǒng)平均每三個(gè)小時(shí)出現(xiàn)一次錯(cuò)誤,訓(xùn)練就會(huì)停止��,修復(fù)問(wèn)題后再重新開始�����。如此反復(fù)�����,可能每隔三個(gè)小時(shí)就會(huì)遇到錯(cuò)誤并重新開始訓(xùn)練。這種情況若無(wú)法有效控制��,訓(xùn)練將陷入無(wú)休止的循環(huán)�����,最終無(wú)法完成任務(wù)��。
過(guò)去�,在高性能機(jī)器應(yīng)用時(shí)���,我們采取了一種策略來(lái)應(yīng)對(duì)頻繁出現(xiàn)的錯(cuò)誤��。例如��,如果預(yù)期系統(tǒng)會(huì)平均三個(gè)小時(shí)出現(xiàn)一次錯(cuò)誤��,我們會(huì)在兩個(gè)半小時(shí)時(shí)主動(dòng)停止訓(xùn)練����。這時(shí)��,我們會(huì)將當(dāng)前的系統(tǒng)狀態(tài)保存到硬盤上�����,然后繼續(xù)執(zhí)行訓(xùn)練。如果訓(xùn)練繼續(xù)到三個(gè)小時(shí)并發(fā)生了錯(cuò)誤�����,以前的做法是從頭開始�,但現(xiàn)在我們可以直接從兩個(gè)半小時(shí)時(shí)保存的狀態(tài)繼續(xù)訓(xùn)練,這樣就省去了重新開始的麻煩���。這個(gè)方法叫檢查上點(diǎn)方法���,在過(guò)去我們已經(jīng)應(yīng)用過(guò)了。然而���,當(dāng)涉及到大模型訓(xùn)練時(shí)����,情況變得復(fù)雜得多����。假如我們?cè)趦蓚€(gè)半小時(shí)時(shí)保存數(shù)據(jù),可能需要花費(fèi)十個(gè)小時(shí)才能完成數(shù)據(jù)的保存過(guò)程�����。數(shù)據(jù)量過(guò)于龐大,導(dǎo)致保存時(shí)間極長(zhǎng)��,這使得我們?cè)谟?xùn)練過(guò)程中����,若在三個(gè)小時(shí)后發(fā)生錯(cuò)誤�,整個(gè)系統(tǒng)就會(huì)陷入混亂,無(wú)法有效繼續(xù)訓(xùn)練�����。
應(yīng)對(duì)這種情況的一個(gè)辦法是在硬盤之前添加一個(gè) USB��,使用 U 盤來(lái)加速數(shù)據(jù)的存儲(chǔ)過(guò)程�。然而,更重要的是要優(yōu)化文件的讀寫速度�����。我們的目標(biāo)是一次檢查點(diǎn)最好能在 10 到 20 分鐘內(nèi)解決問(wèn)題�����。如果不能達(dá)到這個(gè)要求,那么整個(gè)系統(tǒng)的運(yùn)行就難以順利進(jìn)行��,甚至可能無(wú)法完成既定任務(wù)��。
第五��,如果使用國(guó)產(chǎn) AI 芯片�����,還需要做好十個(gè)關(guān)鍵軟件���。前面提到的四個(gè)問(wèn)題,英偉達(dá) AI 芯片也面臨類似的挑戰(zhàn)�。特別是對(duì)于國(guó)產(chǎn)芯片����,這些問(wèn)題更需要得到充分的解決。

如果以上五個(gè)問(wèn)題都得到了妥善處理�,別人可能需要一萬(wàn)塊卡片,而你可能只需要 9000 塊就能達(dá)到相同的效果��。如果這些問(wèn)題沒(méi)有得到充分考慮��,盲目操作的話�,別人用一萬(wàn)塊卡片就能完成的任務(wù)�����,你可能需要三萬(wàn)塊才能實(shí)現(xiàn)�����。




