
7月6日-8日��,信百會2024年度研討會在清華大學經濟管理學院隆重舉行�����。在本次年度研討會主論壇上�,中國工程院院士,清華大學計算機系教授鄭緯民作了題為《算力和存儲是人工智能大模型的基座》的主題演講��。
他詳細介紹了支持大模型訓練的三種算力系統(基于英偉達公司 GPU 的系統���、基于國產通用 GPU 芯片的系統�、基于超級計算機的系統)�����,以及人工智能大模型對存儲的需求與挑戰��。他認為���,設計大模型基礎設施需要考慮五個問題:一是半精度運算性能與雙精度運算性能的平衡���,二是網絡平衡設計,三是內存平衡設計���,四是 IO 子系統平衡設計���,五是如果是國產 AI 芯片的系統,還需要做好編程框架�����、并行加速等 10 個軟件�����?!斑@五點如果做得好,別人要用 1 萬塊卡��,我們用 9000 塊卡就可以了?���!彼赋觥?/span>
(本文根據鄭緯民院士在信百會2024年度研討會上的現場發言內容整理)

人工智能基礎大模型正經歷從單模態向多模態的演進���。最初僅限于文本處理��,隨后擴展到圖像識別��,如今已涉及視頻分析����。人工智能在醫療�����、汽車��、制造��、礦山和氣象等領域的應用正發生顯著變化���。這種發展對算力產生了爆發性需求����,大模型生命周期的每個環節都需要強大的計算能力���。

大模型開發主要包括四個階段:模型開發���、模型訓練、模型精調和模型推理����。在模型開發階段,需要優化程序以提高效率�。模型訓練階段耗時頗長,例如 GPT-4 使用一萬塊 A100 GPU��,訓練時間長達 11 個月���。訓練數據主要來源于互聯網���,涵蓋工業、農業�����、娛樂等多個領域,由此形成的模型稱為基礎大模型�����。模型精調階段則針對特定領域進行專門訓練��,如醫療或金融���,以提升模型在特定領域的表現����。
模型完成后�,在處理用戶請求時也需要大量算力。
無論是模型訓練還是推理�,都對算力有巨大需求。
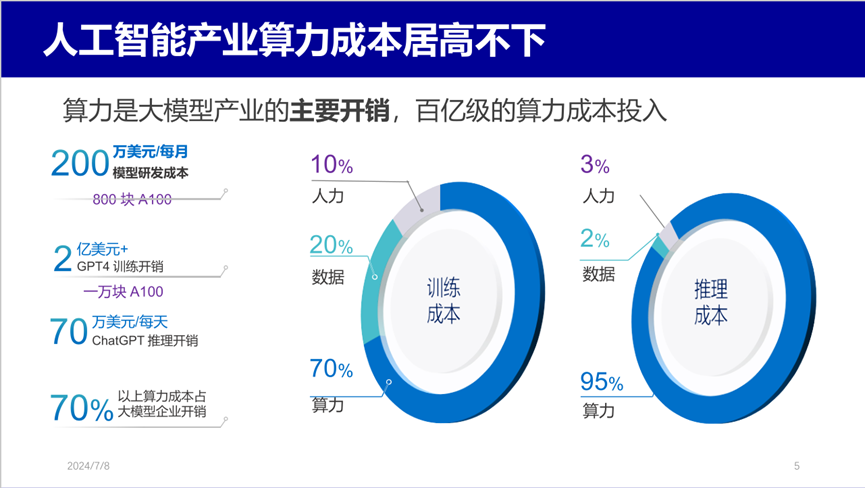
在模型訓練成本中����,算力約占 70%,數據占 20%�����,人力僅占 10%。而在推理階段���,算力成本更是高達 95%���。
目前支持大模型訓練的系統主要有三種:基于 NVIDIA GPU 的系統、基于國產 AI 芯片的系統��,以及基于超級計算機的系統����。NVIDIA 系統因其出色的硬件性能和良好的生態系統而備受青睞����,但由于政治因素,其供應受到限制�����,價格大幅上漲��。近年來���,國產 AI 芯片系統在硬件和軟件方面都取得了顯著進展�����。然而�����,用戶對國產系統的接受度仍然不高��,主要原因在于其生態系統尚未完善�。一個良好的生態系統應當能夠使原本為 NVIDIA 平臺開發的人工智能軟件輕松遷移到國產系統上。目前���,國產系統在軟件兼容性和開發便利性方面仍有待改進��。為改變這一局面�,需要開發好十個關鍵軟件��,以增強國產系統的生態競爭力���。

大模型軟件開發目前面臨多方面的挑戰�,主要包括以下幾個方面:
首先��,框架的構建至關重要�。現代大模型軟件不再直接基于硬件編寫����,而是依賴于框架開發����,這大大提高了開發效率。其次��,并行加速技術亟待提升��。當前的大模型訓練普遍采用多卡并行方式���。雖然我國自主研發的卡性能已達到一定水平,但在并行加速方面仍有待改進���。第三���,通信庫的優化不容忽視。卡與卡之間的通信效率直接影響整體性能����,因此高效的通信庫成為關鍵。第四��,算子庫的完善同樣重要。例如���,高性能的矩陣乘法庫可以顯著提升計算效率�。第五����,AI 編譯器的開發面臨挑戰。將軟件編譯至國產芯片上是一個復雜的過程����,而國內在編譯器領域的專業人才相對匱乏。此外��,還包括編程語言�、調度器、內存分配���、容錯系統���、存儲系統等在內的多個關鍵組件,總計約 10 個核心軟件���。雖然這些軟件都有一定進展����,但或是覆蓋不夠全面,或是質量有待提高���。我一直呼吁����,芯片生產廠商應當主導這 10 個軟件的開發��。只有將這些基礎設施做好���,才能吸引更多開發者使用國產軟件棧����,從而推動整個行業的發展��。
目前���,即便國產計算卡的硬件性能只達到國外產品的 50% 至 60%,只要能夠完善相關的 10 個核心軟件��,仍能獲得客戶的認可和使用����。當前��,用戶對國產計算卡的接受度不高�,主要原因并非硬件性能不足���。事實上�,大多數用戶并未明顯感受到硬件性能的差異��,他們更關注的是生態系統的完善程度����。值得注意的是,即使國產硬件性能超越國外產品 20%��,如果這 10 個軟件未能得到充分開發和優化����,用戶依然會對國產方案望而卻步。因此���,我們可以認識到�,在硬件性能達到一定水平后���,軟件生態系統的建設將成為決定產品成敗的關鍵因素���。
我國目前擁有多個高性能超級計算機系統��,其中科技部正式認定的有 14 個����,實際數量更多�����。這些超級計算機投資巨大����,單臺造價可達 10 億至 20 億元,性能卓越����,為國民經濟發展、國防建設和提升人民生活水平做出了重要貢獻��。鑒于這些高性能計算系統的強大能力���,我們不禁思考:能否將其用于大模型訓練�?這是一個值得探討的問題����。另一個值得關注的現狀是,部分超級計算機的使用率并未達到最高����。針對這一情況,我們進行了一系列實驗��,重點探索軟硬件協同設計的可行性�。軟硬件協同設計的核心理念是:軟件開發人員需深入了解硬件架構,只有這樣���,才能開發出真正高效的軟件��。
以天氣預報軟件為例�����,說明軟硬件協同的重要性�����。早期的天氣預報軟件主要由大氣物理專業畢業生開發的���。當時的計算機硬件相對簡單��,主要依賴 CPU,memory 和磁盤���,開發者只需掌握一門編程語言和基本的數據結構知識即可。然而����,近十幾年來,計算機硬件架構發生了巨大變革����。除了傳統的 CPU,還出現了 GPU�����、TPU�、DPU 以及 SSD 等新型硬件。如果開發者仍局限于傳統的 CPU 知識�,而對新型硬件如 GPU 缺乏了解,那么開發的軟件要么無法正常運行����,要么運行效率極低,無法充分利用硬件資源�。只有當軟件能夠充分利用各種硬件資源,我們才能稱之為實現了真正的軟硬件協同�。這種協同對于提升超級計算機在大模型訓練等領域的應用效率至關重要。
我們在青島的一臺高性能計算機上進行了實驗�����。這臺計算機不僅是我國性能最強的設備��,在國際范圍內也位居前列��。我們選擇將 LAMA 和百川兩個大模型部署到這臺高性能計算機上進行訓練�����,同時確保訓練結果的準確性���。通過對比實驗��,我們發現����,相較于在傳統高性能計算機上進行訓練,將模型在 NVIDIA 的 GPU 上訓練��,成本可以大幅降低至原來的 1/6 左右�。值得注意的是,這臺高性能計算機是國家投資購置的��,用它來進行大模型訓練的成本相對低廉�����。為了說明成本優勢����,我舉例說明:有一家機構在進行大模型訓練時,總計花費了 4500 萬元人民幣�����。這個價格在業內被認為是比較標準的�。然而,我建議他們考慮在青島的這臺高性能計算機上進行訓練���,因為按照我們的計算���,只需要用原來成本的 1/6 就能完成相同的訓練任務�����。對于大模型訓練��,我們并不建議專門購置高性能計算機,因為其成本過高��,可達 20 億元��。這種投資規模通常只有國家級項目才能承擔��。
在大模型的全生命周期中����,存儲系統在每個環節都扮演著至關重要的角色。我們需要從整體角度審視訓練和推理過程��,包括數據的獲取與處理�。亚洲国产精品成人久久久_在线观看中文字幕日韩_中文字幕免费日韩不卡_99V久久综合狠狠综合久久

